The AI market is entering a new phase. For the past several years, attention has centered on models: larger models, smarter models, and faster-moving model releases. As enterprises and service providers move from experimentation to production, the focus is shifting. Increasingly, success in AI depends not only on the model itself, but on the infrastructure used to deploy it efficiently, economically and at scale. That is why the inclusion of Achronix in the Artificial Analysis State of AI Report as an AI accelerator is significant.
The inclusion reflects an important market reality: AI inferencing infrastructure has become a critical part of the conversation. Organizations are no longer evaluating AI platforms based solely on theoretical peak performance or model quality in isolation, but rather on how efficiently those models can be deployed in real environments, under practical constraints, and at scale.
At Achronix, we believe that shift plays directly to the strengths of our approach to AI inferencing.
The Market Is Looking Beyond Models
As generative AI moves deeper into production, infrastructure questions become more urgent:
- How efficiently can it serve models over time?
- How much power, achievable memory bandwidth, and system overhead are required?
- How easily can it be deployed in the data center, private cloud, service provider infrastructure, or edge environment?
- How much control does the customer retain over optimization and deployment?
These are not secondary issues. For production AI, they are often the deciding factors.
Artificial Analysis has become a respected voice in tracking how the AI landscape is evolving across models, systems, and infrastructure. The inclusion of Achronix in the accelerator landscape (see image below) underscores an increasing market emphasis on the hardware platforms that enable AI inference, rather than exclusively on the models dominating public attention.
Why Achronix Belongs in the Conversation
Achronix is included in this discussion because we offer a differentiated path for AI inferencing. Our VectorPath® 815 accelerator card, powered by the Speedster®7t 1500 FPGA, was built to address demanding AI workloads with a focus on low-latency performance, architectural flexibility, and ease of deployment. For organizations deploying large language models, these are not abstract advantages. They are essential to delivering responsive user experiences while maintaining control over infrastructure cost.
The VectorPath 815 combines high-performance FPGA-based acceleration with high memory bandwidth, broad numeric format support, and modern connectivity. It supports low-precision formats important for efficient AI inference, and provides the architectural control needed to optimize around specific workload requirements. That flexibility becomes increasingly important as enterprises look for practical ways to improve inference efficiency and control the cost of deploying LLMs in production. This flexibility enables customers to align the accelerator more closely with the actual needs of LLM inferencing workloads rather than forcing those workloads into a one-size-fits-all architecture.
The ability to align the accelerator matters because LLM inferencing is not simply a compute challenge. It is a system-level challenge shaped by data movement, latency requirements, memory behavior, workload variability, and operating cost. This is also where total cost of ownership becomes central.
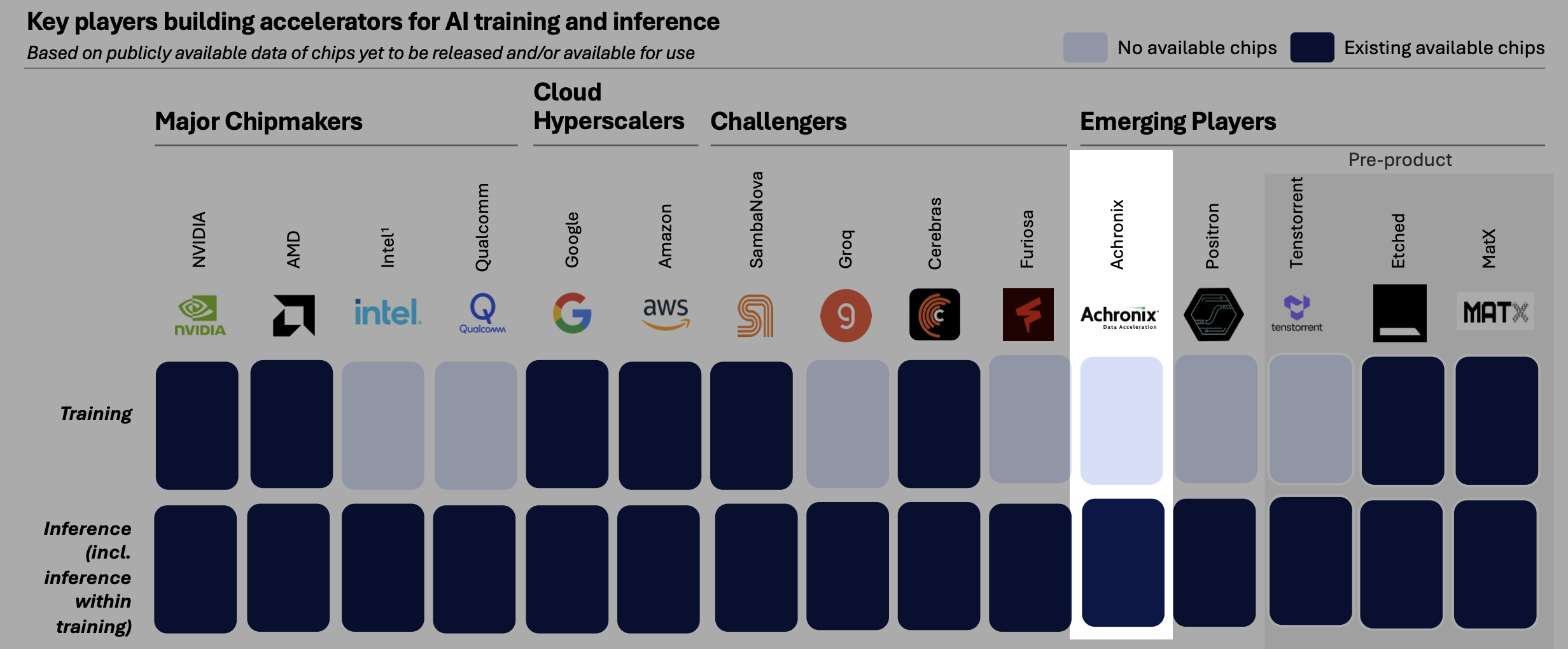
Emerging Players (Image Courtesy of Artificial Analysis)
Total Cost of Ownership Advantages That Matter in Production
As enterprises move from AI pilots to sustained production usage, total cost of ownership (TCO) becomes one of the most important ways to evaluate inference infrastructure. For AI infrastructure buyers, TCO is not just a purchasing metric — it is an operational one, reflecting how efficiently a platform delivers meaningful inference over time while balancing performance, power, utilization, system complexity, and deployment overhead. Achronix is focused on solving that problem.
Lower TCO in LLM inferencing is driven by several practical factors:
- Better infrastructure fit for the workload – LLM inference performance is shaped by more than peak compute. Memory movement, latency behavior, and workload-specific optimization all influence how much useful output an accelerator can deliver. A platform built for these realities can improve efficiency at the system level.
- Support for efficient numeric formats – The ability to support lower-precision inference approaches is increasingly important for improving throughput and reducing infrastructure burden in production AI environments.
- Architectural control – The ability to tailor runtimes, kernels, scheduling, and dataflow around the workload can help eliminate inefficiencies that increase cost over time.
- Deployment flexibility – Infrastructure that can be aligned to the customer's deployment model, whether in the data center, private cloud, service provider environment, or edge, can reduce unnecessary complexity and improve long-term economics.
- A more optimized path to production inference – When infrastructure is designed around real LLM serving requirements, organizations can focus on delivering user value rather than carrying the cost of excess overhead.
These are the kinds of TCO advantages that matter in practice — they are a core part of why Achronix is relevant in today's AI accelerator conversation.
More Than Inclusion — A Signal of Market Relevance
The inclusion of Achronix in the Artificial Analysis report should be understood in the right way. It is not about making exaggerated claims. It is about recognizing that Achronix is part of the accelerator discussion at a time when the AI industry is broadening its view of what matters. The market is moving beyond a narrow focus on peak benchmarks and toward a more complete understanding of inference infrastructure, including latency, deployment flexibility, and TCO.
That is exactly where Achronix brings value.
To learn more about Achronix AI inferencing solutions and how the VectorPath 815 can support your LLM deployment strategy, contact sales@achronix.com.