Machine Learning Processor
Many industries are rapidly adopting artificial intelligence and machine learning (AI/ML) technology to solve many intractable problems not easily addressed by any other approach. The exploding growth of digital data of images, videos, speech and machine generated data, from a myriad of sources including social media, internet-of-things, and videos from ubiquitous cameras, drives the need for analytics to extract knowledge from the data. These data analytics often rely on AI/ML algorithms, which have a unique ability to quickly solve problems of high dimensionality that cannot be solved with classical computer algorithms.
The core of many AI/ML algorithms is pattern recognition, often implemented as a neural network. AI/ML algorithm developers are widely adopting deep convolutional neural networks (DNNs) because these deep networks offer state-of-the-art accuracy for important image classification tasks. AI/ML algorithms generally employ matrix vector math, which requires trillions of multiply/accumulate (MAC) operations per second. Executing these core AI/ML math operations requires many fast multipliers and adders — generally called MAC units.
FPGA as an AI/ML Engine
Achronix's new Speedster7t FPGA family has been designed specifically to meet these challenges. Every aspect of the Speedster7t FPGAs' architecture has been tuned to create an optimized, balanced, massively parallel compute engine for AI/ML applications. Each Speedster7t FPGA feature a massively parallel array of programmable compute elements, organized into new machine learning processors (MLP) blocks. Each MLP is a highly configurable, compute-intensive block, with up to 32 multipliers, that support integer formats from 4 to 24 bits and various floating-point modes including direct support for Tensorflow’s bfloat16 format and block floating-point (BFP) format.
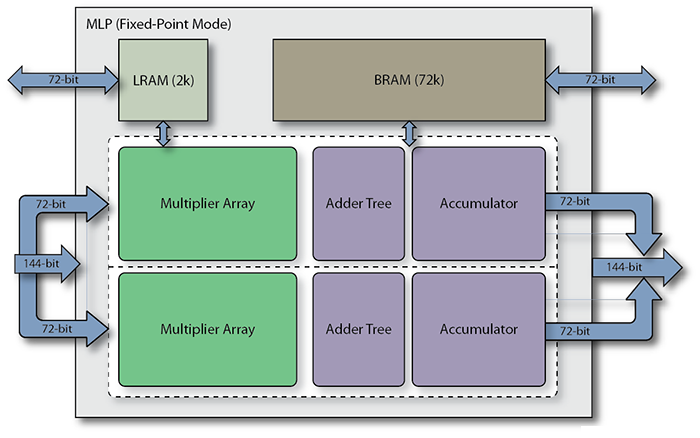
The MLP's programmable MAC incorporates both a fracturable, integer MAC and a hard floating-point MAC. Each MLP block in the Speedster7t fabric also incorporates two memories that are closely coupled to the MAC blocks. One memory is a large, dual-port, 72-kb embedded SRAM (BRAM72k), and the other is a 2-kb (LRAM2k) cyclic buffer. The number of available MLP blocks varies by device, but can number into the thousands.
The MAC's fracturable nature allows it to optimally handle the reduced-precision calculations increasingly used by AI/ML inference algorithms to minimize memory requirements. Due to its fracturable nature, the MLP can perform an increasing number of computations as the precision of the number formats are reduced.
Feature-Rich and Highest Performance Operation
The MLP offers a range of features including integer multiply with optional accumulate, bfloat16 operations, floating point 16, floating point 24, and block floating point 16. Below is a list of features available with the MLP block:
- Fully fracturable integer multiplier/accumulator to efficiently support machine learning inferencing and more traditional applications such as complex adaptive signal processing. Each MLP supports 4x int16, 16x int8 or 32x int4 multiplications. The Speedster7t family supports up to 40,960 int8 MACs resulting in theoretical maximum performance of 61.4 tera-operations per second when running at 750 MHz.
- Flexible floating point is provided to greatly enable numerical precision in calculations. The MLP can be reconfigured to support fp15, fp24 and bf16 number formats for both input and output variables.
- Native support for block floating point is enabled in the MLP. In block floating point, a single exponent is shared across a block of mantissa values. This scheme provides improved dynamic range over fixed-point arithmetic with performance approaching that of traditional floating point, but significantly more efficient. The MLP has dedicated circuitry to enable block floating point numbers to be multiplied, summed and accumulated.
- Highest performance matrix multiplication, exploiting data locality and flow, the MLP includes integrated block RAMs to ensure maximum performance. These memories can be utilized independently, but for MLP multiplication functions, they ensure the highest performance and most power efficient operation by not utilizing the FPGA routing resources. MLPs also include cascade paths between adjacent MLPs to share memories and data for weights or activation data and implementation of efficient data structures such as systolic array architectures.