With the proliferation of data and compute-intensive applications such as machine learning, the high-performance computing (HPC) industry has been growing at a white-hot pace, which was further made clear at SC22 (here are the four HPC trends we took away from the event). Underlying this growth has been a great need for better hardware that can handle these intense computing tasks while providing low latency and high efficiency.
The result of this need has been the emergence of hardware accelerators to the point where today, 83% of sites utilize some form of co-processor/accelerator. While the GPU has become one of the most popular compute accelerators, in practice, GPUs are not always the best acceleration solution for HPC. Instead, there are a number of key reasons why Achronix FPGAs are uniquely well-suited for HPC applications.
Explore some of the major reasons why Achronix FPGAs are an optimal solution for HPC applications below.
Parallelism
One of the primary reasons that GPUs have found success in the HPC space is because of their ability to offer massive parallelism. Parallelism is the ability of a processing unit to process multiple blocks of data simultaneously by providing large numbers of parallel computing resources.
When machine learning and big data started to rise to prominence, the GPU was widely available and libraries were provided directly for ease of adoption, and, as such, it became the default option for many getting started with machine learning. However, FPGAs are an attractive option to deliver equal, if not better performance when compared to GPUs, due to the fixed architecture of the GPU, which supports only SIMD data parallelism and requires batching of the data to take advantage of this fixed architecture, a limitation not shared by FPGAs.
FPGAs are configurable hardware, consisting of thousands of logic and processor blocks that an engineer can program to perform whatever task they desire. With a large number of computing resources available, FPGAs can be configured to offer a level of parallelism that far exceeds CPUs and or even GPUs for certain applications. This parallelism is not only data parallelism, but also task parallelism, meaning the FPGA is a truly parallel architecture that supports multiple concurrent programs processing multiple blocks of data concurrently.
For example, high-performance FPGAs such as the Achronix Speedster®7t AC7t1500 FPGA feature up to 692k LUTs and 2,560 machine-learning processor (MLP) blocks, all of which can be configured to achieve high levels of parallelism to support multiple video or audio streams, streams from multiple storage devices or multiple CPUs, all concurrently.
In this way, FPGAs are well-suited for HPC because they are capable of offering a core requirement: the ability to operate on large amounts of data from multiple sources simultaneously.
Computational Latency
Equally as important as throughput, computational latency is a key enabler of high-performance computing, and this is one place where the FPGA truly shines.
As described by the name, GPUs were originally designed for processing graphics applications but today are considered to be more of a general-purpose parallel computing resource. The problem with general-purpose computing, however, is that depending upon the application, it is simply not performant or power efficient enough to meet the demands. It is this fact that has pushed the industry recently to turn to heterogeneous computing and hardware acceleration, as hardware that is designed for a specific application always outperforms hardware that is general purpose. In addition, the fixed warp-locked architecture of the GPU tends to require batching of data to make efficient use of the hardware which adds latency and makes real-time processing much more difficult.
Being programmable by nature, FPGAs can be reconfigured into specialized computing engines optimized for a given application, effectively custom hardware for each instruction. Whether the task is machine learning, scientific computing, or anything in between, a programmer can configure an FPGA’s fabric to be optimized for a given application. This configurability also means that the FPGA can operate in low-batch or streaming mode very effectively, offering multiple paths of real-time streaming in parallel to deliver the lowest latency possible.
The result is that FPGAs offer HPC hardware with lower latency and higher power efficiency than otherwise possible.
System Latency
A final reason that FPGAs are uniquely well-suited for HPC is their low latency. Beyond the speed of computation, one of the largest inhibitors of HPC performance is the latency associated with moving data throughout the system. As systems simultaneously grow in physical scale as well as in the volume of data being processed, the amount of time spent communicating data from point to point (e.g., in and out of memory, across the backplane, to/from other processing units) grows significantly. The result is that HPC systems can experience a dead time where there is no computation occurring because the system is bottlenecked by the latency of data transport.
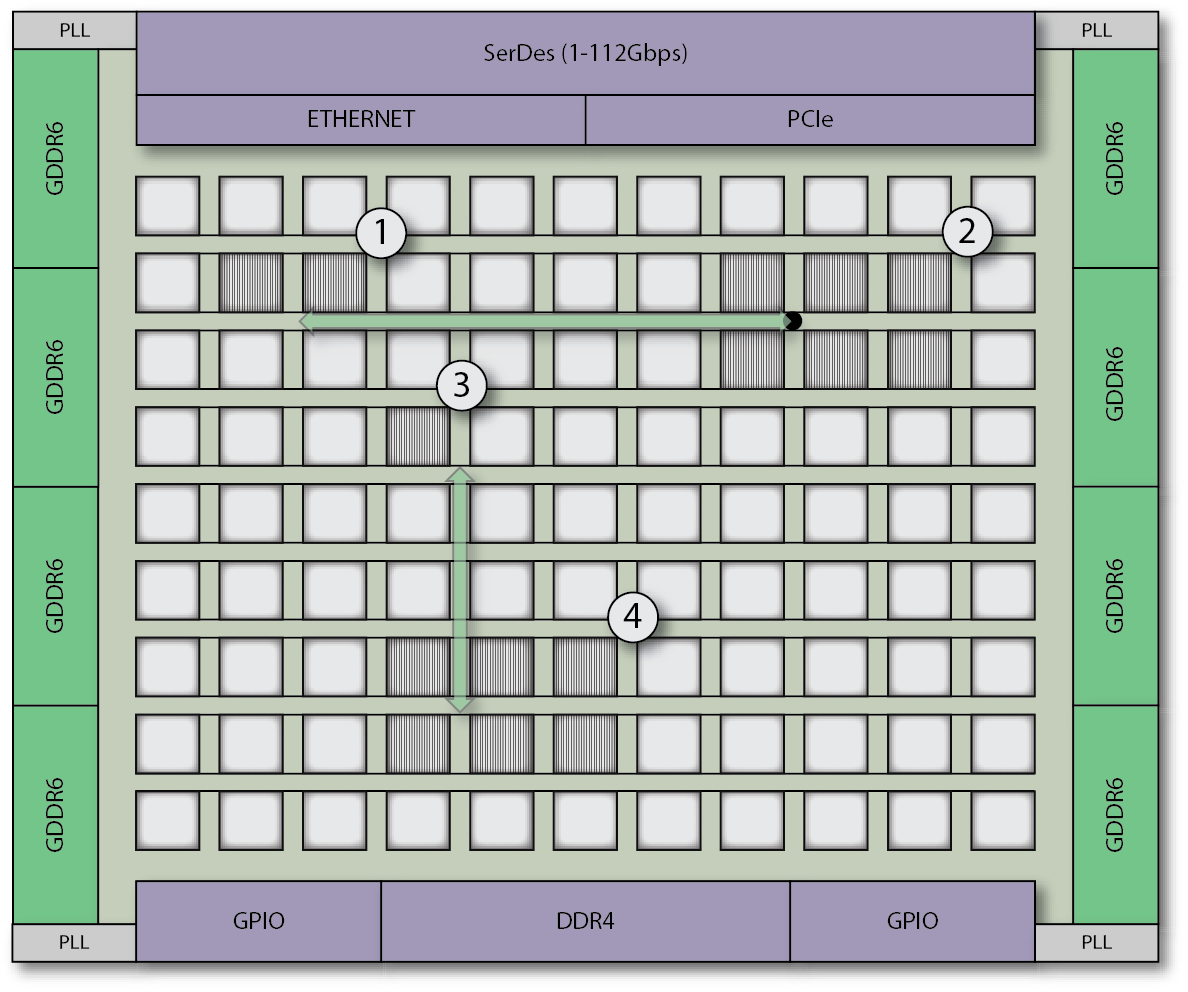
Internal Logic Interconnection Using 2D NoC
As a testament to this fact, today, only 47% of HPC servers currently use 100 GbE for system-to-system communications, while only 15% are using 400 GbE. Achronix FPGA and eFPGA IP offers a unique solution to these challenges in the form of our 2D Network-on-Chip (2D NoC).
The Achronix 2D NoC is a series of high-speed (2 GHz) communication channels in the form of rows and columns that traverse the FPGAs fabric, all connecting to a ring around the fabric providing connections to peripherals in the I/O ring. These channels serve to facilitate extremely fast data transfer and movement throughout the FPGA fabric as well as from external interfaces. Each row or column contains two, 256-bit data paths, each of which can individually support 512 Gbps data rates. Thanks to our 2D NoC, Achronix FPGA and eFPGA technology is capable of achieving an external interface bandwidth of greater than 20 Tbps as well as supporting true 400 Gbps Ethernet.
In addition, Achronix FPGAs can process the data sent directly to it from PCIe, Ethernet, storage devices or other interfaces, without the need of a host to facilitate the data movement. This form of inline processing, allows the FPGA to achieve significantly lower system latency than CPUs and GPUs. The result is that systems featuring Achronix FPGAs can spend less time waiting for data to be transported throughout the system, and instead can spend more time doing actual processing. Hence, FPGA technology improves the performance of HPC systems as compared to other computing resources.
FPGA for HPC
While HPC relies on several unique computing resources, Achronix FPGAs are a uniquely flexible platform for the HPC community. Offering high data and task parallelism, low computational and system latency, high efficiency, and the ability to improve system speeds, Achronix FPGAs are the ideal solution for the future of HPC.