Artificial intelligence (AI) is reshaping the way the world works, opening up countless opportunities in commercial and industrial systems. Applications span diverse markets such as autonomous driving, medical diagnostics, home appliances, industrial automation, adaptive websites and financial analytics. Even the communications infrastructure linking these systems together is moving towards automated self-repair and optimization. These new architectures will perform functions such as load balancing and allocating resources such as wireless channels and network ports based on predictions learned from experience.
These applications demand high performance and, in many cases, low latency to respond successfully to real-time changes in conditions and demands. They also require power consumption to be as low as possible, rendering unusable, solutions that underpin machine-learning in cloud servers where power and cooling are plentiful. A further requirement is for these embedded systems to be always on and ready to respond even in the absence of a network connection to the cloud. This combination of factors calls for a change in the way that hardware is designed.
Let's look at some of the main classes of hardware devices typically used to carry out such computing tasks and analyze the trade-offs associated with each of them:
CPUs
CPUs are about as flexible as a device can be, intended to be a completely general-purpose device. They’re also easy to program. However, this flexibility naturally comes at a cost. The large overhead involved in moving data and instructions around a general-purpose architecture makes CPUs relatively inefficient and power-hungry. As a result CPUs are quickly being left behind in being able to address today’s compute requirements. Designers have therefore chosen to look at other architectures to supplement this generalized functionality.
GPUs
Another route, depending on the task required, is to look at a graphics processing unit (GPU) to solve the problem. GPUs came into their own from the 90s onwards, where they were generally used to aid CPUs in PCs with graphical processing tasks (for which they are architecturally optimized). In fact, GPUs, with their many compute cores and ‘seas of ALUs’, can be used to accelerate many different types of highly parallelized functions. However, the trade-off is an inability to perform generalist compute tasks along with being relatively power-hungry.
ASICs
At the furthest end of the solution spectrum are ASICs. Manufactured specifically to support their target application, ASICs can be designed to waste zero time or energy on anything else. However, the design and manufacturing of an ASIC, as most designers will attest, is expensive, involves high commitment to a limited number of functions, and offers almost no capacity for more generalized compute or adaptation for other uses after the fact.
A huge proportion of our customers are already at this stage — designing high-performance ASICs (as the only means of addressing the intense compute requirements they face). Yet even here, many of the customers that speak to us are already having to think about alternate approaches that might allow them to produce higher-performing devices at a lower overall cost, as well as integrating a degree of functional flexibility.
So what are the alternatives?
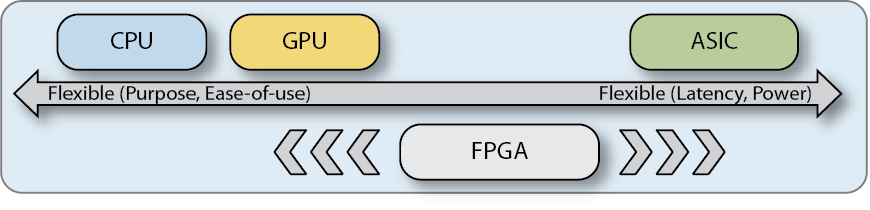
FPGAs
There is another way. FPGAs can offer flexibility close to that of a CPU with the efficiency approaching that of an ASIC. Like ASICs, FPGAs allow the designer to implement the algorithm in logic, delivering huge parallelism and a hardware-optimized solution. Unlike ASICs, FPGAs can be reprogrammed with a new design in the blink of an eye. Compared to CPUs or GPUs, today’s FPGAs are extremely power efficient, able to provide many more operations per watt than processor-based solutions.
But there is an even more attractive solution.
Speedcore eFPGA IP
Achronix has taken things a step further. Rather than simply advocating the use of a discrete FPGA, why not bring that architecture on-board your CPU or SoC and still enjoy further increase in performance?
An eFPGA removes the need to communicate chip-to-chip through bandwidth-limited connections such as PCI-Express and the need for data to be serialized and de-serialized, plus provides an extremely large number of on-chip interconnects to the FPGA fabric — resulting in higher SoC system performance, lower power, reduced die size and overall lower system cost compared to discrete-chip FPGAs.
Achronix’s Speedcore™ eFPGA IP can be integration into ASICs and SoCs to provide a customized programmable fabric. Customers specify their logic, memory and DSP resource needs, then Achronix configures the Speedcore IP to meet their individual requirements. Speedcore look-up-tables (LUTs), RAM blocks and DSP64 blocks can be assembled like building blocks to create the optimal programmable fabric for any given application. Speedcore eFGPAs are currently in production on TSMC’s 16nm process (and in development on TSMC 7nm). Speedcore eFPGAs are supported by the silicon-proven Achronix ACE design tools.
On top of several other benefits, a Speedcore eFPGA solution can offer cache-coherency, share memory resources for faster load-in and load-out, and can reconfigure its entire architecture within 2ms per 100,000 lookup tables.
Existing solutions such as multi-core CPUs, GPGPU and standalone FPGAs can be used to support advanced AI algorithms such as deep learning, but they are poorly positioned to handle the increased demands developers are placing on hardware as their machine-learning architectures evolve. The Achronix Speedcore eFPGA is based upon proven technology and can offer designers a route to faster, smaller, cheaper and more power-efficient solutions, allowing designers to continue to increase their compute in line with rapidly-escalating market requirements.