Today, the advanced driver-assistance systems (ADAS) processor market is growing by more than 25% per year. This growth is driven by the migration of ADAS features – including automatic emergency braking, lane-changing assist, and adaptive cruise-control functions – from luxury vehicles to midrange and even entry-level vehicles. ADAS features will be almost universal by the middle of the next decade. In 2018, several manufacturers offered vehicles with self-driving platforms that delivered better-than-level-2 autonomy including GM’s Super Cruise, Mercedes-Benz’s Distronic Plus, Nissan’s ProPilot Assist, and Tesla’s Autopilot.
As mentioned in part 1 of this blog post, Achronix anticipates that the favored self-driving architecture of the future will be increasingly decentralized, but both the centralized and decentralized architectural design approaches will require hardware acceleration in the form of far more lookaside co-processing than is currently realized. Whether centralized or decentralized, the anticipated computing architectures for automated and autonomous driving systems will clearly be heterogeneous and require a mix of processing resources used for tasks ranging in complexity from local-area-network control, translation, and bridging to parallel object recognition based on deep-learning algorithms running on neural networks. As a result, the current level of more than 100 CPUs found in luxury piloted vehicles could easily swell to several hundred CPUs and other processing elements for more advanced, autonomous vehicles.
Achronix’s Speedcore eFPGA IP can be integrated into ASICs or SoCs targeted at self-driving automotive applications to provide a customized, programmable fabric that delivers hardware-level processing performance. Speedcore eFPGA IP provides the hardware programmability and reprogrammability needed to deal with the rapid evolutionary changes occurring in these autonomous vehicle systems.
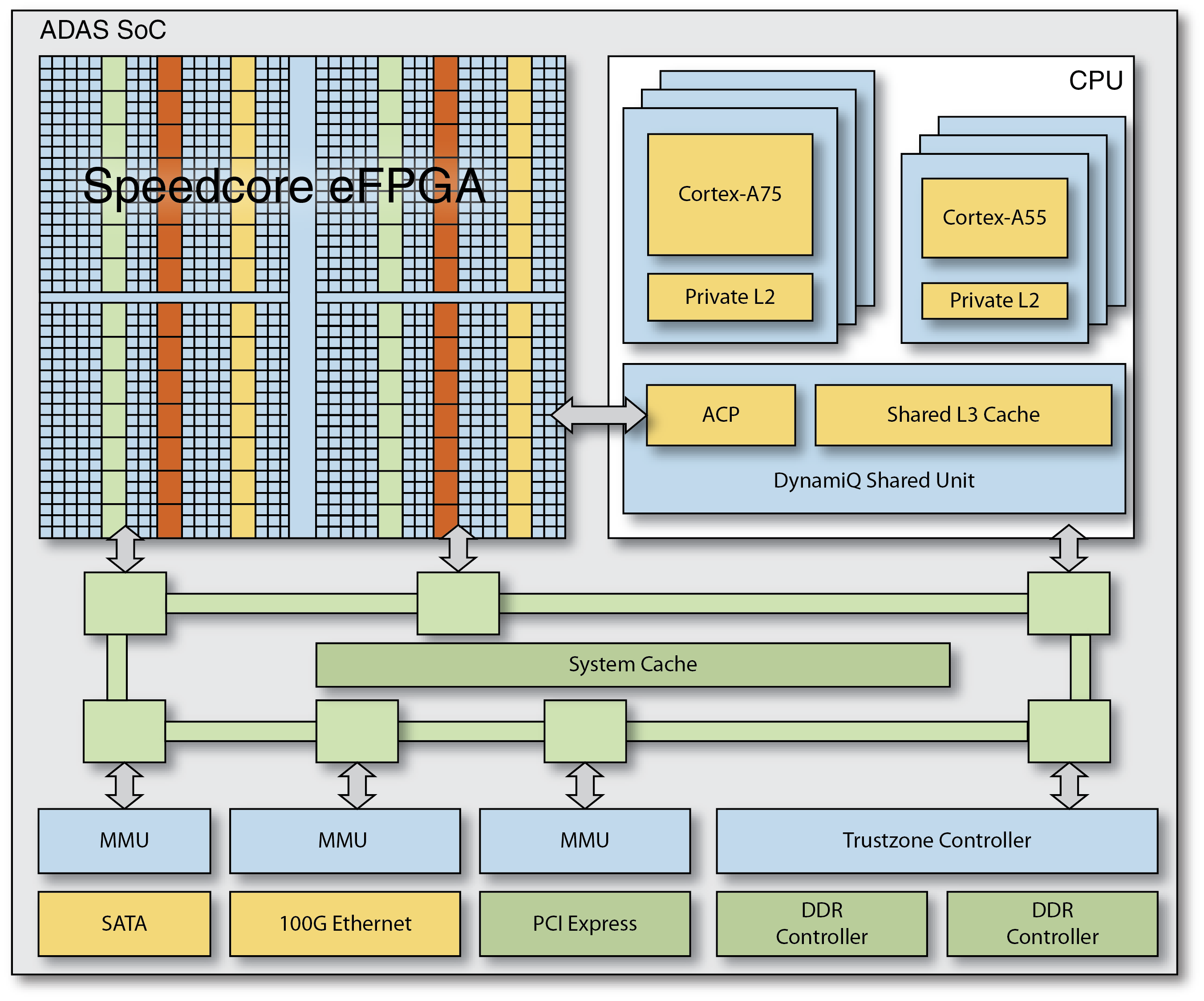
To incorporate Speedcore eFPGA IP into their ASICs and SoCs, designers specify the required logic, memory and DSP resources and Achronix configures a customized Speedcore IP block that meets these requirements. Speedcore look-up-tables (LUTs), RAM blocks, and machine learning processors (MLPs — new with the Speedcore Gen4 architecture) can be assembled like building blocks to create an optimal programmable fabric for any given application.
Incorporating Speedcore eFPGA IP to an ASIC or SoC adds unique design advantages including:
- Programmable hardware resources that permit rapid changes to algorithms running at hardware speeds.
- Resources in the eFPGA can be configured as a programmable offload engine to handle complex algorithms that have not yet become standardized but still must execute at hardware speeds.
- Elimination of ASIC/SoC spins for half- or even full-generation enhancements.
- Higher security in the form of security and cryptography engines that can be modified or upgraded as required.
- The ability to make significant, remote updates to the system design if required.
- Programmable hardware resources that can be used, for example, to implement the programmable BIST engines needed for enumerating the CAN bus. These resources can be reused to implement other functions when the BIST function is not needed.
In the advanced, fully autonomous, self-driving vehicles of the future, the existence of dozens and even hundreds of distributed CPUs and numerous other processing elements is assured. Peripheral sensor-fusion and other processing tasks can be served by ASICs, SoCs, or traditional FPGAs. But the introduction of embedded FPGA blocks, such as the Achronix Speedcore eFPGA IP, provides numerous system design advantages in terms of shorter latency, enhanced security, greater bandwidth, and better reliability that are simply not possible when using CPUs, GPUs, or even standalone FPGAs.
For a deep dive on this topic, refer to the Achronix white paper titled How to Meet Power, Performance and Cost for Autonomous Vehicle Systems using Speedcore eFPGAs (WP015).