Achronix Vice President and Chief Technologist, Raymond Nijssen, and Senior Principal Engineer, Michael Riepe, attended this year's virtual FPGA 22 Conference (February 27 – March 1, 2022) — an event predominantly focused on the use of FPGAs as data accelerators in AI, ML, genomics, and high-level synthesis. Two keynotes and various sessions later, we sat down to talk to them about their top takeaways from the event — one focused heavily on the data acceleration capabilities and a roadmap of FPGAs in the semiconductor industry.
Top Four Takeaways from the Virtual FPGA 22 Conference
1. Approaching the Angstrom Era with the Continued Advance of Semiconductor Processes
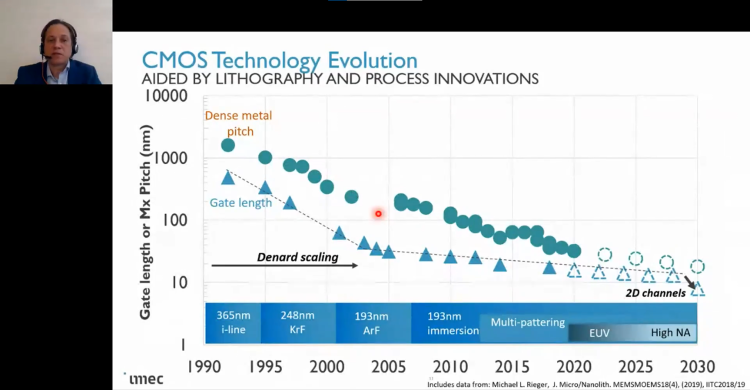
A keynote from Zsolt Tőkei, a Fellow and Director of Nano Interconnects at Interuniversity Microelectronics Centre (imec), gave us designers a few rays of hope for the continued advance of semiconductor processes as we approach the angstrom era. Current state-of-the-art technology consists of FinFET devices and dual damascene interconnects using EUV lithography. Zsolt ensures us that scaling will continue to drive performance and efficiency, and that will continue for at least the next 10 years. In fact, we will get back some of the sacrifices we've made over the last few process generations. After FinFETs, we will see so-called gate-all-around (GAA), or "nanosheet" devices with stacked horizontal gates rather than fins.
In addition to reduced area, designers get back the knob that lets them change the gate width. After the nanosheet, we might see a technology called a "forksheet" that adds a dielectric sidewall between the N and P devices to further reduce area and capacitance. Following the forksheet, we might even see complementary FETs (CFETs) that stack or fold the N and P devices vertically as well.
On the interconnect side, Zsolt predicts a move from current dual-Damascene (DD) technology to a new semi-Damascene (SD) process under development at imec. DD was optimized for cost, not RC. With a fixed aspect ratio, it can't be co-optimized for both power and data. SD technology, when combined with air gaps and alloy vias, allows the aspect ratio to be varied with almost no capacitance increase while achieving decreased resistance. We can also look forward to backside power delivery, with power rails buried below the fins. You'll no longer need to drill 12 layers of vias down from top-level metal, benefiting from reduced resistance and area.
Zsolt closed by mentioning that the semiconductor industry is starting to look at reducing its carbon footprint, quantifying emissions by adding it as a new metric when making process decisions.
2. Machine Learning Accelerator ASIC
In a second keynote, Satnam Singh from Groq gave us a peek under the hood of their machine learning accelerator ASIC, as well as the compiler techniques used to make it run. In an entertaining talk full of Scottish folk dancing analogies, Singh showed us how they take maximum advantage of the property that ML workloads can be statically scheduled. This aspect allows their dataflow architecture to be carefully tuned, with data flowing in intricate patterns like a carefully choreographed dance. Their architecture actually looks surprisingly similar to an FPGA, with repeating patterns of functional blocks and distributed memories arranged in columns. Data flows east and west, between functional blocks and scratchpad memories, with instructions flowing north and south. Groq achieves high performance by keeping data in flight for as long as they can before it must be written back to off-chip memories. These chips are also designed to be snapped together like Lego blocks, scaling performance smoothly over larger systems based on multiple chips, cards, and racks.

3. Domain-Specific Applications Architectures and Advanced Techniques in High-Level Synthesis
Similar to previous years, the majority of the conference was devoted to the application of FPGAs as domain-specific compute accelerators. Achronix targets this market directly with its FPGA and eFPGA IP offerings, as both of these technologies are uniquely suited to address the needs of high-performance compute and high-bandwidth applications. This application of FPGAs was reflected in two broad themes: architectures for various domain-specific applications such as machine learning and genomics, demonstrating that FPGAs can beat CPUs and GPUs in those domains; and new advanced techniques in high-level synthesis, demonstrating improvements in making FPGA design accessible to programmers as well as digital designers.
A best-paper candidate by Erwei Wang et. al. from Imperial College London and Cornell University, followed the first theme, looking at improving upon the state of the art in direct-mapped DNN architectures, in which the LUTs act directly as trainable neurons. Previous work has shown this architecture to be competitive in area and performance, but it results in dense networks of random connections that are still suboptimal. This team developed a method of learned sparsity, called "Logic Shrinkage", introducing incremental netlist pruning into the training algorithm that maximized the number of zero-weight edges that can then be removed. On one network they achieved a 2.67× area reduction.

Following the second theme, Licheng Guo et. al. from UCLA, Ghent University, Cornell, and Xilinx, discuss an implementation called RapidStream that aims to eliminate the large gap between CPU and FPGA compilers. Using a dataflow analysis of the pipeline stages of a HLS description, they break the design up into relatively independent pieces that can be synthesized, placed, and routed in parallel, and then stitched back together. They achieved 5-7× improvment in place-and-route runtimes, while increasing clock frequencies by a factor of 1.3.

4. High Bandwidth Memory — Processing-in-Memory (HBM-PIM)
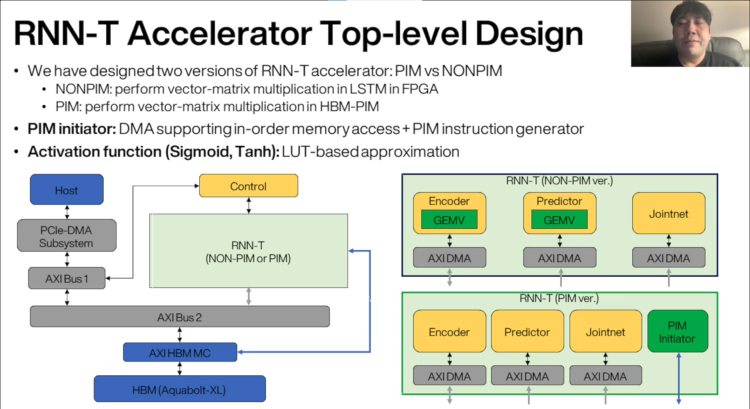
Authors from Samsung and Inha University presented a paper with the title “An FPGA-based RNN-T Inference Accelerator with PIM-HBM”. It shows how they accelerated an RNN-T engine by adding programmable numerical processing engines between the memory arrays of the DRAM slices in an HBM stack. This architecture exploits the much higher memory access bandwidth available inside the DRAM arrays, namely by not having to go through the bandwidth bottleneck between the DRAM arrays and the application logic in the host chip. Instead, instructions for these processing engines are sent from the application logic to the memory to perform this processing-in-memory (PIM) method, directly operating on the data that no longer needs to be transported back and forth between the DRAM and the FPGA. The authors show compelling speedup results for the selected application. Moreover, much energy is saved by keeping the data local. It would be very interesting to find out if this approach can be applied more generally to other applications, including non-numerical functions.
Wrapping it Up
Our major takeaway from this year's FPGA 22 Conference is that the future looks extremely bright for the FPGA and eFPGA market. Innovations in transistor technology will allow future generations of devices to improve in performance and efficiency. Being able to rely on scaling for improvements, as we have for decades, ensures a level of predictability and consistency for future technology. We are optimistic that future Achronix products, such as our Speedcore or Speedster7t products, can reliably harness these benefits to achieve higher densities, performance, and power efficiency.
At the same time, compute intensive applications such as ML will continue to drive the need for FPGAs as domain-specific accelerators. Serving alongside CPUs and GPUs, and in many cases outperforming them, FPGAs and eFPGAs will be necessary building blocks of future high-performance computing applications. In this context, Achronix offerings, including our VectorPath Accelerator Card, will only become more valuable for future computing infrastructure.
Raymond and Michael look forward to connecting with everyone again next year (hopefully in-person) in Monterey, California.