Within the dynamic and powerful field of conversational artificial intelligence (CAI), automatic speech recognition (ASR) is one of the fastest-growing areas with the potential to make the most impact on businesses. Today, CAI and ASR are already ubiquitous with virtual assistants, chat bots and other automated solutions present in most consumer electronics. And this only scratches the surface of what's possible. Still, there are many challenges that need to be solved before CAI can take on its full potential to revolutionize our world.

Building Blocks of Conversational AI
Earlier this month, our team spoke at the annual Conversational Interaction Conference to share the Achronix perspective and direction in the field of CAI. He specifically presented on the reduction of speech transcription costs by up to 90% with CAI, which you can review in our latest white paper. Below we discuss the computing needs to make CAI a reality, and how Achronix is working to solve the many challenges in the field.
The Need for Low Latency in CAI
One of the most exciting applications for CAI and ASR is in the call center, which has recently been re-labeled as the contact center to reflect the current state of the technology. Here, CAI technology has addressed a myriad of customer service challenges including quality control, real-time answering and automated call summary reports enabled by ASR and NLP just to name a few.
Yet, for CAI to be truly transformative requires the ability to perform the machine learning (ML) algorithms used for the ASR, natural language processing (NLP) and speech synthesis in real-time. As he explained, “...one of the real challenges with CAI is doing it in real-time so that it's a natural transaction between someone who's speaking and getting the results that they want.”
Without real-time CAI, services such as those provided by contact centers will feel sluggish and unnatural, leading to a poor user experience. Hence, achieving high-performance, realistic CAI requires extremely low-latency performance and response. Better automation also leads to reduced time per call, lowering operational costs of contact centers.
Challenges Facing CAI
Achieving this low-latency, real-time, high-performance capability has historically proven to be difficult, and, at the heart of this challenge is the ability to move data between memory and compute sub-systems efficiently at very high bandwidths exceeding 10 Tbps.
Fundamentally, many of the ASR, NLP, and speech synthesis algorithms used in CAI today are based on ML algorithms. Recurrent neural networks (RNNs) are common for ASR with the RNN-transducer, or RNN-T, one of the more popular algorithms. The feedback nature of an RNN and its use in real-time applications results in the weights stored in the sub-system memory of the FPGA accelerator being frequently passed to the compute engine of the accelerator. This transaction creates a memory-bound scenario — the enormous amount of data movement becomes a significant bottleneck in trying to achieve the required low latency.
He elaborates, telling the conference “As we start to build larger datasets, we can become more intelligent. But as we do that, we're going to need better computation. And we're going to need more memory. And we're going to need hardware systems that can move the data between the compute and memory sub-systems of the FPGA accelerator. Achronix is addressing this need with its best-in-class Speedster7t FPGA platform.”
FPGAs and Achronix for Conversational AI
Broadly, most ASR service providers will run their ML algorithms either on a cloud computing service such as AWS or Azure or on their own servers (on premise). In either scenario, real-time CAI is attainable through the use of hardware acceleration
Hardware acceleration devices will be architected with a compute engine, either using electronic gates or some type of compute subsystem such as ARM, RISC-V or other approach. Either an internal HBM or external DDR or, in the case of Speedster7t, GDDR6 memory subsystem will be used to move ML algorithm weights in and out of the compute engine.
For certain ML algorithms, such as RNNs, and, more importantly, for real-time applications, the ability to move data between the memory and compute subsystems of the accelerator will be critical to get the effective compute performance and meet the application's requirements. Tight coupling with the memory subsystem is crucial to minimize or eliminate the data movement bottleneck that exists in many of today's solutions.
These devices can be GPUs, ASICs, or FPGAs. FPGAs are more efficient with RNNs versus GPUs as an RNN and its feedback approach result in poor utilization of GPU resources which reply on heavy parallelism.
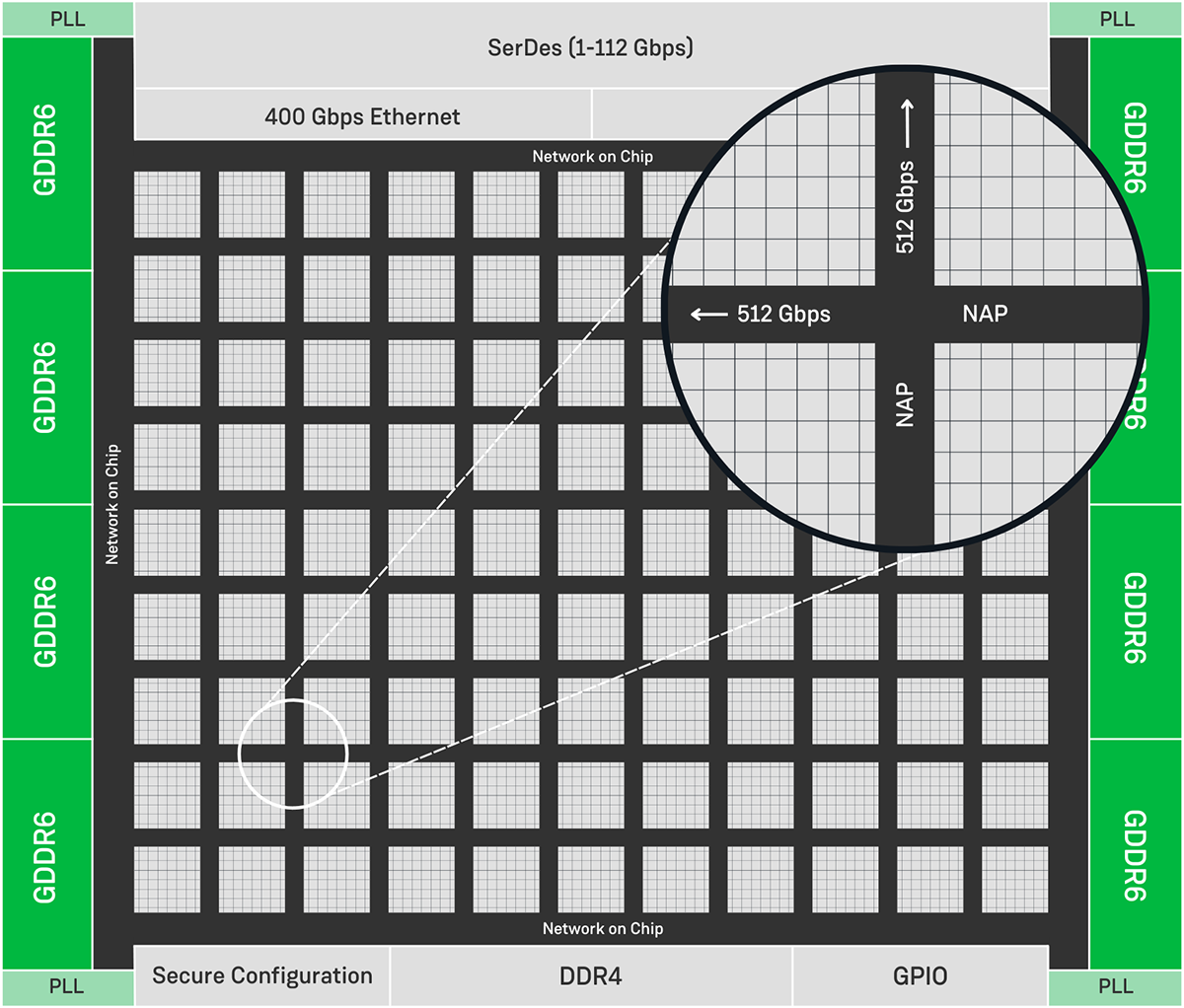
Achronix 2D NoC Technology Achieves an Aggregate Bandwidth of 20 Tbps
For these reasons, we feel that FPGAs are the optimal solution for enabling real-time, low-latency CAI systems. Compared to other FPGAs, Achronix Speedster7t FPGAs have been designed to offer the right balance of compute, memory and data movement. Enabled by our two-dimensional network on chip (2D NoC) supplying 20 Tbps of bi-directional bandwidth, Speedster7t FPGAs provide optimal data routing between memory and compute.
This impressive bandwidth allows us to create systems that offer high compute performance without suffering from the bottlenecks associated with data movement. Most recently, we have shown that our technology can support up to 4000 real-time streams (RTSs) on one PCIe card integrated onto a single server. The impact here is improved performance, scalability, and cost-efficiency within the data or contact center.
It's clear that the future of CAI is going to require hardware acceleration, and within this, we feel that our FPGAs are uniquely positioned to provide the best performance possible.