Computational Storage
Computational storage solutions enhance traditional storage subsystems with more capabilities to reduce data movement and optimize performance and efficiency. The Speedster7t family of FPGAs allow you to create solutions to perform powerful data plane services at the storage, like indexing, searching, or even analyzing data with AI/ML algorithms. You can also provide more traditional storage data plane service like encryption, compression, and deduplication.
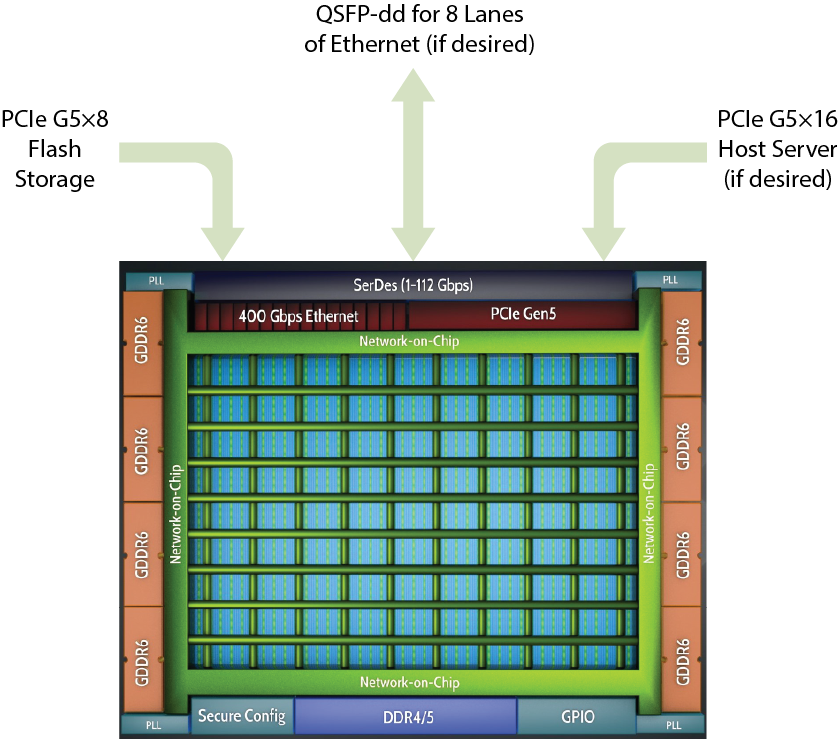
Computational storage leverages Speedster7t FPGA’s ability to move massive amounts of data in, out, and around the chip as well as the large computational throughput of the FPGA fabric. This can substantially increase the system performance and saves moving data around the data center.The Speedster7t FPGA family is optimized for high-bandwidth workloads and eliminates the performance bottlenecks associated with traditional FPGAs. Built on TSMC’s 7nm FinFET process, Speedster7t FPGAs feature a revolutionary new 2D network-on-chip (NoC), an array of new machine learning processors (MLPs) optimized for high-bandwidth and artificial intelligence/machine learning (AI/ML) workloads, high-bandwidth GDDR6 interfaces, 400G Ethernet and PCI Express Gen5 ports — all interconnected to deliver ASIC-level bandwidth performance while retaining the full programmability of FPGAs.
Speedster7t Solution
With Speedster7t there are many connectivity options leveraging the many lanes of high-speed SerDes along with PCIe Gen5 controllers. One PCIe controller can be connected to a host server while another is connected to flash storage for NVMe solutions. The chip also has Support for 400G Ethernet for NVMeOF solutions.
Using the both the PCIe and Ethernet together allows for creating of computational storage solutions where the storage devices can collaborate with their own network to distribute data and computation for optimal performance. This allows for offloading of even more complexity and optimizations from the host servers.
Speedster7t FPGAs have up to 8 GDDR6 controllers, which allow for over 4 Tbps of DRAM bandwidth enabling both high-performance caching solutions and high performance tables for services like deduplication. The DRAM bandwidth can help enable storage solutions to keep up with the high bandwidth of PCIe Gen5 and 400G Ethernet, with buffers that can match the peak bandwidth of these next generation interfaces.
Reconfigurable fabric is well suited for the data plane optimizations for computation storage and support updating algorithms in the field as solutions evolve. The new Speedster7t NoC provides the ability to gracefully move data around the chip and in and out of the fabric to keep up with the high bandwidth demands for computational storage solutions. Additionally, the high throughput encryption/decryption IP available in Speedster7t FPGAs allow for building secure solutions without sacrificing performance. The Speedster7t MLPs and reconfigurable fabric enable computation storage applications that accelerate machine learning in both today's and tomorrow's systems.
| Application Requirements | Speedster7t Value |
|---|---|
| Programmable controller for new flash memories |
|
| Wide and high performance data-path |
|
| Compression/Deduplication |
|
| Encryption/Decryption |
|
| Data indexing and Data search |
|
| AI/ML data analysis |
|
| Caching |
|
| NVMe Controller |
|
| NVMeOF Controller |
|
| Encryption | Compression/ Deduplication |
Data Indexing and Searching | AI/ML analysis | Caching | NVMe Controller | NVMeOF Controller | |
|---|---|---|---|---|---|---|---|
| Highest Performance SerDes | |||||||
| 112G multi-Standard SR/MR/LR PHY | Yes | Yes | |||||
| Ultra-Short Reach (USR), eXtra-Short reach (XSR) | Yes | Yes (Silicon Photonics) | |||||
| Most Advanced Interface IP | |||||||
| 400G Ethernet - 16 lanes each running up to 100G | Yes | ||||||
| PCIe Gen5 | Yes | Yes | Yes | ||||
| GDDR6 - 4 Tbits/sec of memory bandwidth | Yes | Yes | Yes | Yes | Yes | Yes | |
| DDR4 - up to 3,200 MHz, 3DS stacked memory | Yes | Yes | Yes | Yes | Yes | Yes | |
| DDR5 - up to 4,400 MHz | Yes | Yes | Yes | Yes | Yes | ||
| Terabit Speed Routing | |||||||
| Network on Chip | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Bus Routing | Yes | Yes | Yes | Yes | |||
| Fully flexibility bit wise routing | Yes | Yes | Yes | Yes | |||
| High Throughput Processing | |||||||
| Packet Processor/Traffic Manager | Yes | ||||||
| Datapath crypto | Yes | ||||||
| Machine Learning Processor | Yes |